

A Inteligência Invisível que Molda o Nosso Mundo
Você já se perguntou como a Netflix recomenda exatamente o filme que você queria ver? Ou como o Spotify cria uma playlist semanal que parece ler sua mente? E o que dizer dos assistentes de voz que entendem e respondem às suas perguntas? Por trás de toda essa mágica digital está uma das áreas mais revolucionárias da tecnologia moderna: o Machine Learning (Aprendizado de Máquina).
Longe de ser apenas um conceito de ficção científica, o Machine Learning é o motor que impulsiona a inteligência artificial (IA) em nosso dia a dia. É a ciência que ensina os computadores a aprender com dados, identificar padrões complexos e tomar decisões de forma autônoma, sem serem explicitamente programados para cada tarefa.
Este guia completo foi criado para ser o seu mapa nesse universo fascinante. Partindo de uma estrutura visual, vamos explorar cada canto do Machine Learning, desde seus pilares fundamentais — Aprendizado Supervisionado, Não Supervisionado e por Reforço — até os algoritmos específicos que dão vida a essa tecnologia. Se você é um estudante, um profissional de tecnologia ou simplesmente um curioso sobre o futuro, prepare-se para uma jornada do básico ao avançado.
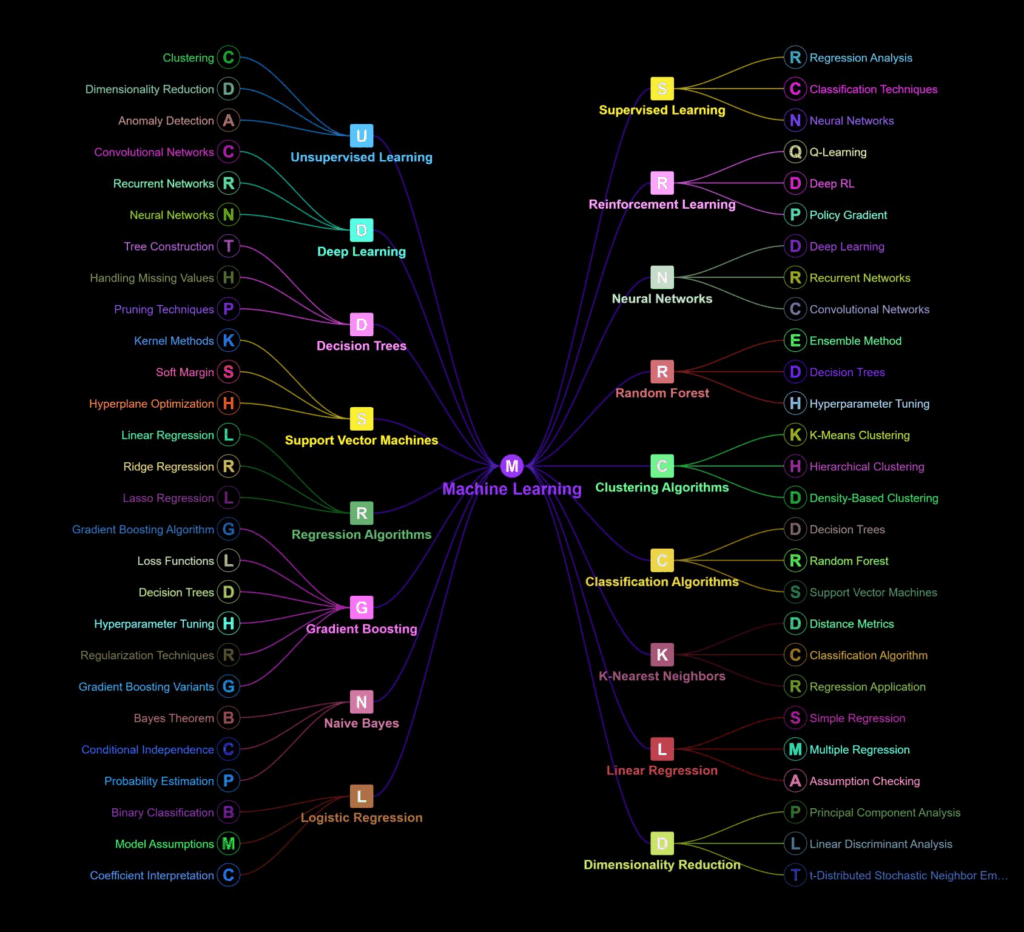
1. O Ponto de Partida: O Que é, Afinal, Machine Learning?
No seu núcleo, Machine Learning é um campo da IA que se baseia na ideia de que sistemas podem aprender com dados. Em vez de um desenvolvedor escrever regras de código rígidas para resolver um problema (ex: “SE o e-mail contiver a palavra ‘oferta’, ENTÃO é spam”), o desenvolvedor cria um algoritmo que analisa milhares de exemplos de e-mails (dados) e aprende por conta própria as características que definem um spam.
O processo geralmente envolve duas fases:
- Treinamento: O modelo é alimentado com um grande volume de dados para aprender os padrões inerentes a eles.
- Inferência (ou Previsão): O modelo treinado é usado para fazer previsões ou tomar decisões sobre novos dados nunca antes vistos.
Essa capacidade de generalizar a partir de exemplos é o que torna o Machine Learning tão poderoso. Para organizar esse vasto campo, dividimo-lo em três grandes paradigmas de aprendizado, cada um com uma abordagem e um propósito diferentes.
2. Aprendizado Supervisionado: Aprendendo com um Professor
O Aprendizado Supervisionado é a abordagem mais comum e intuitiva. Imagine que você está ensinando uma criança a reconhecer animais. Você mostra a ela uma foto de um gato e diz “isto é um gato”. Depois, uma foto de um cachorro e diz “isto é um cachorro”. Após muitos exemplos, a criança aprende a identificar os animais por conta própria.
Nessa analogia, os “exemplos” são os dados de treinamento, e os “rótulos” (“gato”, “cachorro”) são as respostas corretas que o modelo deve aprender. O algoritmo é “supervisionado” porque tem um gabarito para seguir. Esta abordagem se divide em duas tarefas principais:
a) Análise de Regressão: Prevendo Valores Contínuos
O objetivo da regressão é prever um resultado numérico e contínuo.
- Exemplos: Prever o preço de uma casa com base em sua área e localização, estimar o número de vendas de um produto no próximo mês ou prever a temperatura de amanhã.
- Algoritmos Comuns:
- Regressão Linear (Linear Regression): O algoritmo mais fundamental, que tenta modelar a relação entre variáveis usando uma linha reta. Sua simplicidade é sua força, mas depende de certos pressupostos do modelo (Model Assumptions) para funcionar bem.
- Ridge Regression & Lasso Regression: Variações da regressão linear que introduzem técnicas de regularização para evitar o “overfitting” (quando o modelo se ajusta demais aos dados de treino e perde a capacidade de generalizar). A Lasso Regression tem a vantagem adicional de poder realizar a seleção de features, zerando o impacto de variáveis menos importantes.
b) Técnicas de Classificação: Prevendo Categorias
A classificação visa atribuir um rótulo ou uma classe a um dado de entrada. A saída é discreta.
- Exemplos: Classificar um e-mail como “spam” ou “não spam”, diagnosticar se um tumor é “benigno” ou “maligno”, ou identificar o sentimento (positivo, negativo, neutro) em um comentário online.
- Os algoritmos de classificação são a espinha dorsal de muitas aplicações de IA, e exploraremos os mais importantes mais adiante neste artigo.
3. Aprendizado Não Supervisionado: Descobrindo Padrões Ocultos
E se não tivermos um gabarito? E se tivermos apenas um amontoado de dados e quisermos encontrar algum sentido neles? É aqui que entra o Aprendizado Não Supervisionado. O algoritmo explora os dados por conta própria para descobrir estruturas, padrões e anomalias ocultas, sem nenhum rótulo prévio.
a) Clusterização (Clustering)
A clusterização é a tarefa de agrupar dados semelhantes. O algoritmo cria “clusters” ou grupos onde os membros de cada grupo são mais parecidos entre si do que com os membros de outros grupos.
- Aplicação Prática: Uma empresa de e-commerce pode usar a clusterização para criar segmentos de clientes (ex: “compradores de alto valor”, “compradores ocasionais”, “buscadores de promoções”) e direcionar campanhas de marketing personalizadas para cada grupo.
- Algoritmos:
K-Means Clustering,Hierarchical Clustering,Density-Based Clustering.
b) Redução de Dimensionalidade (Dimensionality Reduction)
Imagine uma planilha com centenas ou milhares de colunas (dimensões). Trabalhar com tantos dados pode ser computacionalmente caro e ineficiente, um problema conhecido como a “maldição da dimensionalidade”. A Redução de Dimensionalidade busca simplificar esses dados, reduzindo o número de variáveis e mantendo a informação mais importante.
- Algoritmos Principais:
- Análise de Componentes Principais (PCA): A técnica mais famosa. Ela cria novas variáveis, os “componentes principais”, que são combinações das variáveis originais e capturam o máximo de variância possível nos dados.
- Análise de Discriminante Linear (LDA): Similar ao PCA, mas é uma técnica supervisionada. Ela encontra as projeções que melhor separam as diferentes classes.
- t-SNE: Uma técnica poderosa usada principalmente para a visualização de dados de alta dimensão em gráficos 2D ou 3D.
c) Detecção de Anomalias (Anomaly Detection)
Esta técnica foca em identificar pontos de dados que são raros e se desviam significativamente do padrão normal. É crucial para tarefas de segurança e manutenção.
- Aplicações: Detecção de fraudes em cartões de crédito, monitoramento de falhas em equipamentos industriais, detecção de intrusos em redes de computadores.
4. Aprendizado por Reforço: Aprendendo com Tentativa e Erro
O Aprendizado por Reforço (Reinforcement Learning – RL) é o mais diferente dos três. Inspirado na psicologia comportamental, ele se concentra em um agente que aprende a tomar decisões em um ambiente para maximizar uma recompensa. O agente não recebe um gabarito, mas aprende através das consequências de suas ações — um sistema de recompensas e punições.
Pense em treinar um cachorro: ele ganha um petisco (recompensa) quando senta, mas não ganha nada quando late. Com o tempo, ele aprende que a ação de “sentar” leva a um resultado positivo.
- Conceitos-Chave:
- Q-Learning: Um algoritmo clássico que aprende a “qualidade” (Q-value) de uma ação em um determinado estado, ajudando o agente a escolher o melhor caminho.
- Policy Gradient: Métodos que otimizam diretamente a “política” (a estratégia de decisão) do agente.
- Deep Reinforcement Learning (Deep RL): A fusão do RL com Deep Learning. Aqui, redes neurais profundas são usadas para permitir que o agente aprenda em ambientes extremamente complexos, como jogar xadrez ou Go em nível de mestre (AlphaGo), controlar carros autônomos ou gerenciar sistemas robóticos.
5. Deep Learning: A Revolução das Redes Neurais Profundas
Deep Learning não é um tipo de aprendizado, mas sim um subcampo do Machine Learning que levou a avanços espetaculares na última década. Sua base são as Redes Neurais (Neural Networks), modelos computacionais inspirados na estrutura do cérebro humano. O que torna o Deep Learning “profundo” é o uso de redes com muitas camadas de “neurônios”, permitindo que aprendam hierarquias de características de forma automática.
a) Redes Neurais Convolucionais (CNNs)
As CNNs são as estrelas da visão computacional. Elas são projetadas para processar dados em formato de grade, como imagens. Usando filtros matemáticos chamados “convoluções”, elas aprendem a identificar características simples nas primeiras camadas (como bordas e cores) e combiná-las em características mais complexas nas camadas seguintes (como formas, texturas e objetos inteiros).
- Aplicações: Reconhecimento facial, carros autônomos, diagnóstico médico por imagem.
b) Redes Neurais Recorrentes (RNNs)
Enquanto as CNNs são especialistas em espaço, as RNNs são especialistas em sequências. Elas possuem um tipo de “memória” que permite que a informação de um passo anterior influencie o passo atual. Isso as torna ideais para dados onde a ordem importa.
- Aplicações: Processamento de linguagem natural (tradução automática, chatbots), reconhecimento de fala, análise de séries temporais (previsão do mercado de ações).
6. Um Mergulho nos Algoritmos Essenciais de Machine Learning
Além das grandes áreas, o universo do Machine Learning é populado por algoritmos específicos, cada um com suas forças e fraquezas. Vamos conhecer os mais importantes:
- Árvores de Decisão e Modelos Ensemble:
- Árvores de Decisão (Decision Trees): Um dos modelos mais intuitivos. Funciona como um fluxograma de perguntas “se-então-senão” para chegar a uma decisão. Sua principal vantagem é a interpretabilidade.
- Random Forest: Para evitar que uma única árvore “erre” sozinha, o Random Forest utiliza o conceito de método de ensemble: ele constrói uma “floresta” de centenas de árvores de decisão e combina seus resultados (através de votação para classificação ou média para regressão). O resultado é um modelo muito mais robusto e preciso.
- Gradient Boosting: Outro poderoso método de ensemble. Ele constrói árvores de forma sequencial, onde cada nova árvore é treinada para corrigir os erros da anterior. Algoritmos como XGBoost e LightGBM, baseados em Gradient Boosting, são frequentemente os vencedores em competições de ciência de dados.
- Support Vector Machines (SVMs): Um algoritmo de classificação elegante e poderoso. O SVM trabalha encontrando o hiperplano de otimização, que é a “linha” ou plano que melhor separa os dados das diferentes classes com a maior margem possível. Com o uso de Kernel Methods, ele consegue separar até mesmo dados que não são linearmente separáveis.
- K-Nearest Neighbors (KNN): Um algoritmo simples e baseado em instâncias. Para classificar um novo ponto, ele olha para os seus “K” vizinhos mais próximos (definidos por uma métrica de distância) e atribui a classe que for majoritária entre eles.
- Naive Bayes: Um classificador baseado no Teorema de Bayes. Ele faz uma suposição “ingênua” (naive) de que todas as variáveis de entrada são independentes umas das outras. Apesar dessa simplificação, é surpreendentemente eficaz, especialmente em tarefas de classificação de texto, como filtros de spam.
- Regressão Logística (Logistic Regression): Não se engane pelo nome. Este é um algoritmo fundamental para classificação binária. Ele não apenas classifica, mas também realiza a estimação de probabilidade, informando a chance de um item pertencer a uma determinada classe. A interpretação dos seus coeficientes permite entender o impacto de cada variável na decisão final.
Conclusão: O Futuro é Autodidata
Percorremos um longo caminho, do núcleo do Machine Learning até suas extremidades mais complexas. Vimos como os computadores podem aprender sob supervisão, descobrir padrões sozinhos ou aprender por tentativa e erro. Exploramos a revolução do Deep Learning e detalhamos o arsenal de algoritmos que os cientistas de dados usam para resolver os problemas mais desafiadores do mundo.
O Machine Learning não é mais uma promessa futura; é uma realidade presente e transformadora. Cada algoritmo e técnica que exploramos é uma peça no quebra-cabeça da inteligência artificial, uma ferramenta que, quando usada com sabedoria, tem o potencial de impulsionar a inovação em todas as áreas do conhecimento humano. O futuro não será apenas programado; ele será aprendido.
Palavras-Chave Sugeridas para WordPress
Primárias:
- Machine Learning
- Aprendizado de Máquina
- Inteligência Artificial
- Guia de Machine Learning
- Algoritmos de Machine Learning
Secundárias:
- Aprendizado Supervisionado
- Aprendizado Não Supervisionado
- Aprendizado por Reforço
- Deep Learning
- Redes Neurais
- Análise de Regressão
- Técnicas de Classificação
- Clusterização de Dados
- Redução de Dimensionalidade
- Detecção de Anomalias
Específicas (Long-tail):
- O que é Regressão Linear
- Como funciona o Random Forest
- Aplicações de Redes Neurais Convolucionais
- Diferença entre PCA e LDA
- O que é Q-Learning
- Support Vector Machines explicado
- Gradient Boosting vs XGBoost
- Teorema de Bayes em Naive Bayes
- Processamento de Linguagem Natural com RNNs
- Modelos de Ensemble em Machine Learning

